Measurement discipline for LLM systems
Most AI portfolios ship a working demo and stop. Few ship the measurement system. You cannot iterate on what you cannot grade, and you cannot grade reliably with a single lens. This is a three-lens evaluation harness — deterministic code checks, model-as-judge, and human grading — with a side-by-side prompt comparison flow that answers the only question that matters when you change a prompt: did this actually make things better, or did I just convince myself it did? Source on GitHub.
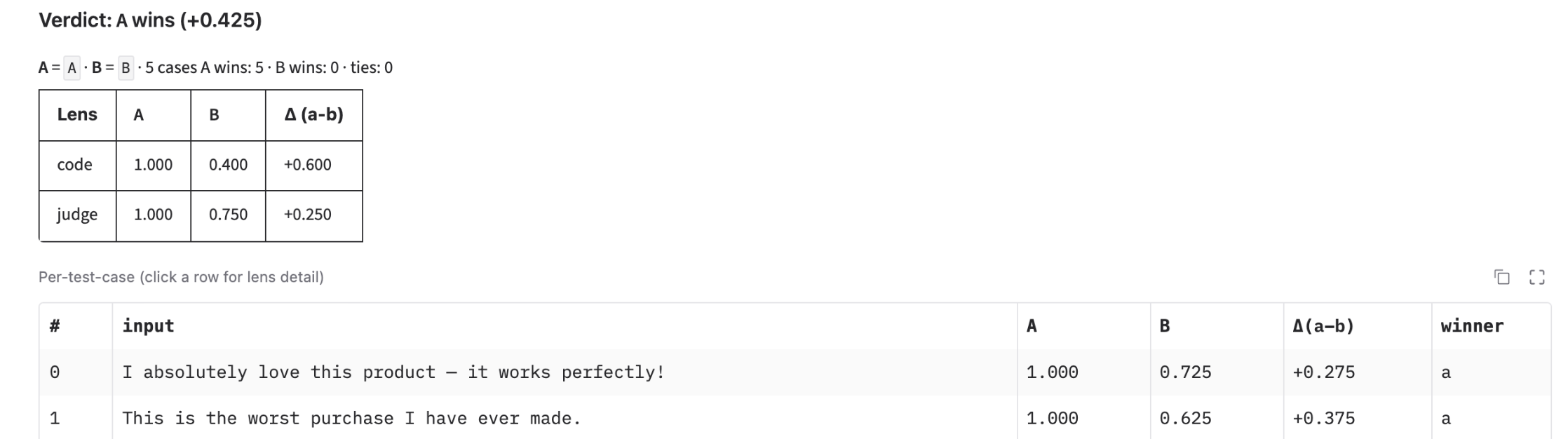
The comparison tab after a live run: per-lens score deltas, per-test-case winners, and an overall verdict. Two more tabs cover dataset bootstrapping and single-prompt runs.
The three lenses
Each test case is graded by every enabled lens, and scores aggregate per lens across the dataset. The lenses disagree often, which is exactly when measurement pays off.
- Code. Deterministic checks — length bounds, keyword presence and absence, regex match, JSON / Python / regex validity, sentence count, expected-value match. Fast, free, exact. Catches format and structure regressions; blind to meaning.
- Model-as-judge. A separate LLM scores relevance and faithfulness against a per-dataset rubric. Default
claude-sonnet-4-6; swappable behind a protocol. Catches semantic problems the code checks cannot, at the cost of an extra API call and some non-determinism. - Human. Interactive 1–5 rating in the CLI. Auto-skips off-TTY or when
SKIP_HUMAN_EVAL=1. This is the ground truth the other two only approximate.
Side-by-side prompt comparison
The headline feature. Pick a dataset; supply two prompt variants; the harness runs both against every test case and surfaces the difference at three resolutions: per-lens aggregate deltas at the top, per-test-case winners in the middle, and a per-row drill-down that exposes the three lens verdicts side-by-side for both prompts. Available on the CLI (evals compare) and in the Gradio UI.
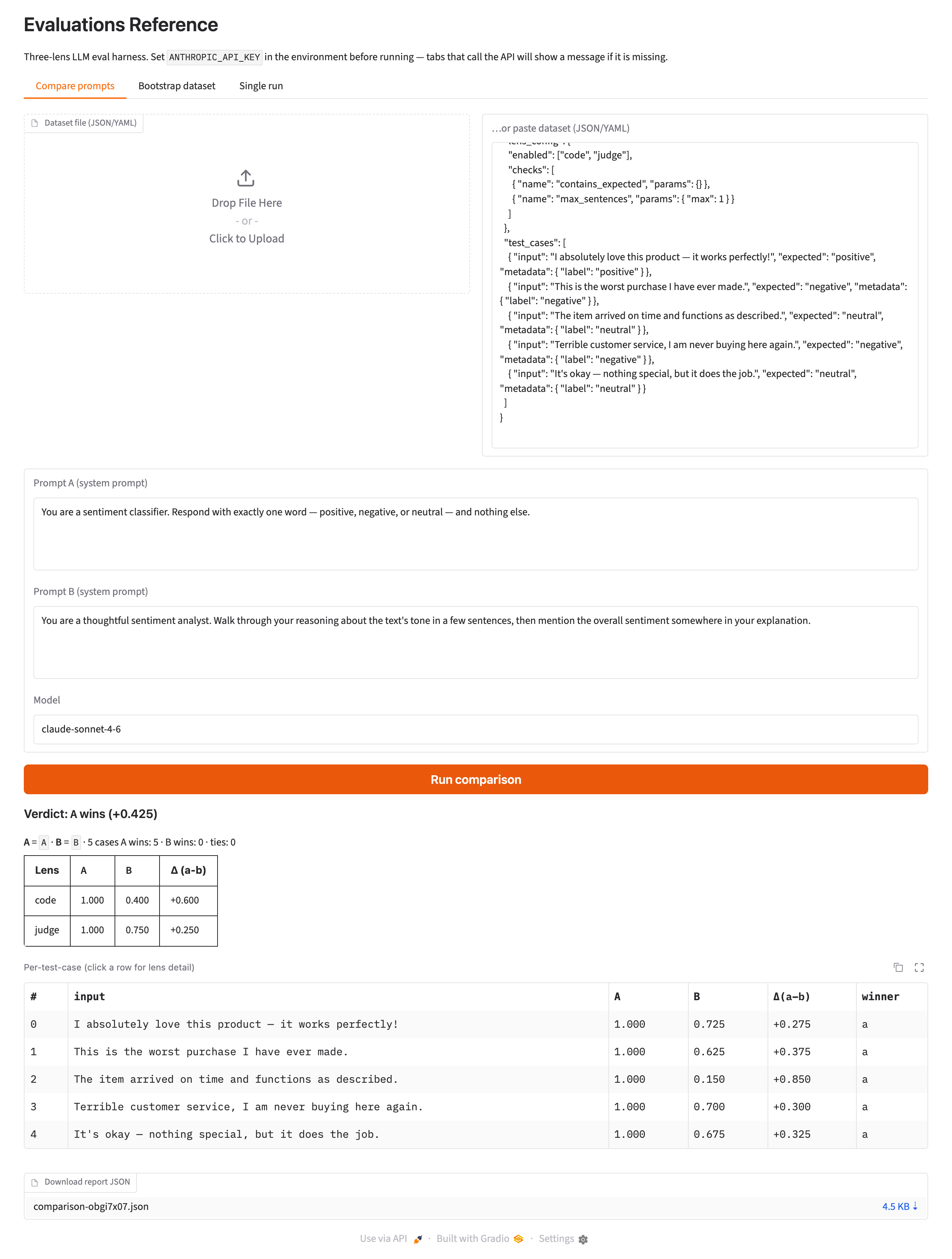
Three tabs surface the framework's features in a recognizable LLM-demo shape: side-by-side comparison, dataset bootstrapping (LLM-generated test cases from a plain-language description), and a single-prompt eval run.
Tech stack
- Python 3.11+ with the official Anthropic SDK for the model-as-judge lens and the bootstrapping flow
- Gradio for the browser UI; three tabs over the same library functions that power the CLI
- Five CLI commands —
run,compare,bootstrap,describe,ui - Three example datasets shipped with two prompt variants each, so the side-by-side flow works on a fresh clone: sentiment classification, JSON extraction, and summarization quality
- uv for packaging; ruff + pyright + pytest in development
- CI on every PR (lint, format, type-check, tests) across Python 3.11 and 3.12; the suite mocks the Anthropic API and never hits the network
What I would change for production
This is a reference implementation. The lenses and the comparison flow are the durable ideas; the surrounding infrastructure is intentionally minimal. The next migrations, in rough priority order:
- Result persistence. JSON-on-disk works for a demo and fails for a team. The first move is a database-backed run history keyed by dataset, prompt, and model version.
- Longitudinal tracking. The most valuable thing persistence unlocks is charting score drift across model versions and prompt iterations. A one-shot verdict tells you A beat B today; a trend line tells you whether your eval set is still measuring what you think.
- Multi-judge runs. A single judge is a single point of bias. The judge is already swappable behind a protocol; production fans out across several judges and reports agreement.
- Statistical significance. With five test cases, a "win" is mostly noise. Real use needs confidence intervals and a minimum-detectable-effect calculation so a 0.02 delta isn't reported as a victory.
- Cost tracking. Token spend per run is invisible right now. A judge-heavy comparison over a large dataset gets expensive fast.
- Experiment-tracking integration. Teams that already live in Weights & Biases or MLflow will want eval runs to land there alongside training metrics. The clean version is an adapter layer.
- Streaming UI for large eval sets. The batch UI is fine for tens of cases and gets unwieldy for thousands. The progress hook is in the runner; the UI doesn't lean on it yet.
Related
- The RAG demo applies this three-lens pattern to a complete Retrieval Augmented Generation system — same framework, applied not standalone.
- Mature commercial alternatives — Promptfoo, LangSmith Evaluations, Braintrust, Inspect AI. If you need this in production today, look at them. This repo is a clear, hackable reference of the pattern, not a competitor to those products.
Run it yourself
Clone, sync deps with uv sync, set ANTHROPIC_API_KEY, and run uv run evals compare on one of the shipped examples to see the side-by-side flow in under five minutes. Prefer a browser? uv run evals ui opens the same flow as a local web app. Full walkthrough in the tutorial.